Problem n-królowych
Algorytmy z powrotami, OpenMP, wielowątkowość...

OpenMP - Zrównoleglanie kodu
Automatyczne zrównoleglanie kodu
W zależności od architektury komputera równoległego oraz sposobu, w jaki organizuje on dostępną pamięć operacyjną,
zależy też sposób jego oprogramowywania. Inaczej pisze się programy pod maszyny z pamięcią współdzieloną, a inaczej
z pamięcią rozproszoną. Jedną z najprostszych technik wykorzystywania mocy drzemiącej
w komputerach równoległych jest tzw. automatyczne zrównoleglanie kodu na poziomie kompilatora (realizowane za pomocą
odpowiednich flag i opcji). Kompilator analizuje program i wyszukuje zestawy niezależnych instrukcji, a także
niezależnych iteracji
w pętlach "for"1 podatnych na zrównoleglanie. Przy aplikacjach o nieskomplikowanej budowie, ta prosta metoda
zrównoleglania dobrze spełnia postawione przed nią zadanie. Jednak przy bardziej złożonych projektach programistycznych,
okazuje się praktycznie bezużyteczna. Wynika to z faktu, że kompilator nie jest w stanie automatycznie wychwycić
wszystkich operacji wymagających zrównoleglenia i z tego powodu stopień zrównoleglenia kodu (a co za tym idzie
przyśpieszenie skompilowanego programu) jest relatywnie na niskim poziomie.
Zrównoleglanie bloków instrukcji
Zrównoleglanie kodu za pomocą OpenMP nie odbywa się w sposób automatyczny. Służą do tego specjalne
dyrektywy kompilatora, których programista używa do określenia miejsc i obszarów w kodzie programu,
jakie mają ulec zrównolegleniu. Mamy więc do czynienia ze wspomnianym już wcześniej "zrównoleglaniem
przyrostowym". Inną zaletą stosowania dyrektyw kompilatora jest ich "przeźroczystość" dla kompilatora.
Jest to bardzo przydatne w sytuacjach, gdy w kompilatorze występują kłopoty z obsługą wielowątkowości.
Przypuśćmy, że chcemy skompilować program pod kompilatorem, który nie posiada biblioteki do obsługi
dyrektyw OpenMP. Okaże się, że program zostanie skompilowany prawidłowo. W tego typu sytuacjach dyrektywy
OpenMP są po prostu pomijane, a program kompiluje się bez użycia wielowątkowości.
Najistotniejszą i zarazem najbardziej podstawową konstrukcją OpenMP jest dyrektywa OMP PARALLEL. Służy
ona do wyznaczenia bloku instrukcji w kodzie programu, które mają zostać wykonane w sposób równoległy.
Części programu nie objęte dyrektywą OMP PARALLEL, będą wykonywane sekwencyjnie. Kiedy główny wątek
programu dotrze do obszaru zrównoleglania, natychmiast powołuje do życia nową grupę wątków, z którą
wspólnie rozpoczyna równoległe przetwarzanie danych3. Wątek, który odkrywa jako pierwszy istnienie
obszaru zrównoleglania, staje się liderem nowopowstałej grupy wątków. Jest to wątek typu master. Każdy
wątek posiada swój unikalny numer, służący do jego identyfikacji w grupie. Numeracja rozpoczyna się
od 0 (wątek typu master) do n-1, gdzie n to maksymalna ilość wątków, określana przez programistę w
trakcie uruchamiania programu.
#pragma omp parallel
{
// obszar zrównoleglania
}
// obszar kodu wykonywany sekwencyjnie
Zrównoleglanie pętli "for"
Wiedząc już jak łatwo możemy wprawić w ruch serię wątków i zaprząc je do równoczesnej pracy na określonym
bloku danych, warto przyjrzeć się kolejnej konstrukcji OpenMP, która znacznie rozszerza możliwości zrównoleglania
kodu. Chodzi o dyrektywę OMP FOR, która służy do równoległego przetwarzania danych w pętlach for. Jest to
najpopularniejsza konstrukcja z zestawu dyrektyw OpenMP. Za jej pomocą, możemy podzielić pracę związaną z
wykonywaniem kolejnych iteracji pętli for pomiędzy różne wątki. W efekcie, wykonywanie pętli odbywa się
znacznie szybciej. Jedynym ograniczeniem konstrukcji OMP FOR jest liczba iteracji, a dokładnie czy jest to
wartość znana przed wprawieniem w ruch pętli for. Aby wątki mogły przetwarzać dane równolegle, to wartość
ta musi być z góry ustalona. Poniżej znajduje się ciekawy przykład kodu ilustrującego sposób, w jaki iteracje
mogą być dystrybuowane między różnymi wątkami.
#pragma omp parallel
{
#pragma omp for
for (i=0; i<9; i++)
printf("Wątek %d przetwarza iterację numer: %d\n",
omp_get_thread_num(),i);
}
Zadaniem powyższej pętli for jest rozdzielenie pracy związanej z przetworzeniem dziewięciu iteracji pomiędzy grupę kilku wątków. Wynikiem działania pętli są informacje wyświetlane na ekranie. Dzięki nim dowiemy się, która iteracja była obsługiwana przez jaki wątek. Do określenia numeru aktualnie działającego wątku używać można funkcji omp_get_thread_num(). Po uruchomieniu programu dla 3 wątków (czyli grupy wątków o numerach 0,1,2), pętla for może zwrócić następujące wyniki:
Wątek 0 przetwarza iterację numer: 0 Wątek 0 przetwarza iterację numer: 1 Wątek 0 przetwarza iterację numer: 2 Wątek 1 przetwarza iterację numer: 3 Wątek 1 przetwarza iterację numer: 4 Wątek 1 przetwarza iterację numer: 5 Wątek 2 przetwarza iterację numer: 6 Wątek 2 przetwarza iterację numer: 7 Wątek 2 przetwarza iterację numer: 8
Jak widać, iteracje zostały równomiernie rozdzielone pomiędzy dostępne wątki. Aby mieć pełną kontrolę nad sposobem dystrybucji zadań (iteracji) między wątkami stosuje się klauzulę schedule. Dzięki niej, jesteśmy w stanie z góry określić ile iteracji przypadnie do przetworzenia na jeden wątek. Co więcej, możemy także wskazać sposób łączenia wątków z kolejnymi blokami iteracji. Standardowo wątki przypisywane są statycznie (static), zaczynając od wątku z numerem 0, który przetwarza pierwszy blok iteracji. Następne bloki przypisywane są kolejnym wątkom według ich numeru identyfikacyjnego. Jeżeli bloków iteracji jest więcej niż wątków, nadwyżka ta przydzielana jest po kolei wszystkim dostępnym wątkom (zaczynając od wątku 0). Aby lepiej zilustrować strategię statycznego przydzielania wątków do bloków iteracji, zmodyfikowano nieco kod pętli for z poprzedniego przykładu.
#pragma omp parallel
{
#pragma omp for schedule (static,2)
for (i=0; i<9; i++)
printf("Wątek %d przetwarza iterację numer: %d\n",
omp_get_thread_num(),i);
}
Założono, że każdemu wątkowi będą przydzielone po dwie iteracje do przetworzenia (liczbę tą określa dodatkowy
parametr w klauzuli schedule). Wynik działania tak zmodyfikowanej pętli dla trzech wątków może wyglądać
następująco:
Wątek 0 przetwarza iterację numer: 0 Wątek 0 przetwarza iterację numer: 1 Wątek 0 przetwarza iterację numer: 6 Wątek 0 przetwarza iterację numer: 7 Wątek 1 przetwarza iterację numer: 2 Wątek 1 przetwarza iterację numer: 3 Wątek 1 przetwarza iterację numer: 8 Wątek 2 przetwarza iterację numer: 4 Wątek 2 przetwarza iterację numer: 5
Wyniki nie są ułożone w poprawnej kolejności, wynika to z braku synchronizacji wyświetlania komunikatów za pomocą funkcji printf.
Nie jest to jednak ważne, sednem tych wyników są pary cyfr określające przynależność kolejnych iteracji do konkretnych wątków.
Każdy wątek otrzymał po kolei dwie iteracje do przeanalizowania. Z racji większej liczby bloków iteracji niż wątków, wątek 0
otrzymał dwa bloki (0-1 oraz 6-7), zaś ostatnią, ósmą iteracje wykonał następny w kolejności, wątek 1.
Statyczne przypisywanie iteracji to nie jedyna metoda zrównoleglania pętli for.
Wątki mogą dynamicznie pobierać określone partie iteracji i je przetwarzać. W takim przypadku nie można przewidzieć z góry
jakie iteracje zostaną przydzielone którym wątkom. W pętli for zrównoleglonej trybem dynamic, wątki nie otrzymują już ściśle
określonych iteracji do przetworzenia. Wiedzą jedynie jak duży blok iteracji pozwalamy im pobrać i przetworzyć. Kolejność
przydzielania wątkom bloków iteracji jest zależna tylko od tego, który wątek aktualnie jest wolny i gotowy do pracy. Każdy
wątek, po pomyślnym ukończeniu przetwarzania bloku iteracji zgłasza żądanie przydzielenia mu następnej porcji danych. Dzięki
dynamicznemu przydzielaniu pracy, wątki działają znacznie efektywniej. Nie ma przestojów w obliczeniach, ponieważ każdy wątek
po ukończeniu przydzielonej mu pracy pobiera i przetwarza kolejną porcję danych. Nie dochodzi też do sytuacji,
w której szybsze wątki kończą pracę i są bezczynne, czekając na wolniejszych "kolegów", którym statycznie przydzielono
trudniejszą porcję iteracji do przeanalizowania.
Pewną interesującą modyfikacją dynamicznego przetwarzania iteracji jest tryb guided. Zachowuje się on dokładnie tak samo
jak dynamic, z tą różnicą, że porcje danych przydzielane wątkom zmniejszają się wykładniczo. A więc z każdym kolejnym
przydziałem danych, wątki otrzymują mniej pracy.
Ostatnim trybem mającym wpływ na sposób przetwarzania pętli for jest klauzula runtime. Za jej pomocą możliwe jest
sprecyzowanie sposobu zrównoleglania pętli for dopiero w czasie uruchamiania programu. Odbywa się to za pomocą zmiennej
środowiskowej OMP_SCHEDULE. Zmienna ta może przyjmować wartości: static, dynamic lub guided. Ograniczeniem typu runtime
jest brak możliwości określenia jak duże bloki iteracji mają być przydzielane kolejno między wątki.
Wszystkie trzy główne metody równoległego przetwarzania pętli for zilustrowane zostały na poniższym wykresie (rys. 1).
Widać na nim, w jaki sposób może zachowywać się grupa czterech wątków w starciu z pętlą for wykonującą się 500 razy.
Pętla zrównoleglona jest po kolei w trybie guided, dynamic a na końcu static. Blok iteracji składa się z pięciu obrotów pętli.
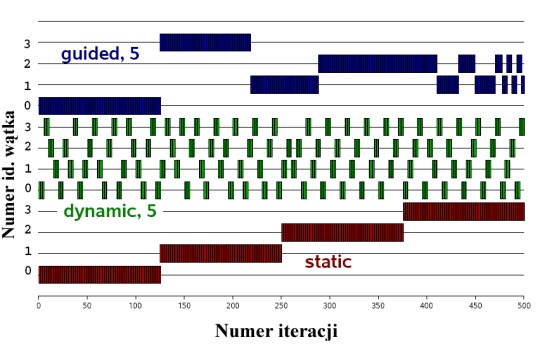
Rys. 1. Zrównoleglanie pętli for w trybie guided, dynamic i static.
1 B. Chapman, G. Jost, R von der Pas, Using OpenMP - Portable Shared Memory Parallel Programming, MIT Press, Londyn 2008, s. 15.
2 M. Demichowicz, P. Mazur, OpenMP - środowisko programowania komputerów równoległych ze wspólną pamięcią, NAKOM, Poznań 2002, s. 112.
3 B. Chapman, G. Jost, R von der Pas, Using OpenMP - Portable Shared Memory Parallel Programming, MIT Press, Londyn 2008, s. 54.